How did Twingate stay up when the cloud broke?

Hint: Multi-cloud or hybrid cloud isn't enough.
Is it too soon to talk more about the Thursday, June 12, 2025 cloud outage? At Twingate, we love cloud services. Our cloud partners are critical to the scalability, ease of use, and security of Twingate... But they are not enough.
On June 12th, Google Cloud suffered a major outage that triggered a cascade of outages across the Internet, impacting the likes of Cloudflare, UPS, Spotify, Discord, and even Pokemon. But Twingate just kept running.
All cloud builders know what a major outage means: the triage, the fix, the apology tour, post-mortems. The true impact of outages extends far beyond the immediate technical problem:
Every incident derails development timelines by weeks.
Teams get pulled into endless damage-control meetings.
Sales, Support, and CS teams bear the emotional weight of frustrated customers.
Team morale takes a massive hit.
Because Twingate is the global network layer for our customers, any Twingate outage has an outsized impact. If we go down, our customers can’t access the resources they need to get work done.
So, when the June 12th outage erupted, we fired up the incident Zoom (as someone said, “I’m surprised this meeting is even working.”). We watched and waited for the alerts.
And Twingate just kept running. We had a range of alerts. We had our action plan ready-to-go and automation to pull in all the data needed to take action. Our team experienced the outage as end-users and as observers, but the Twingate service was not affected.
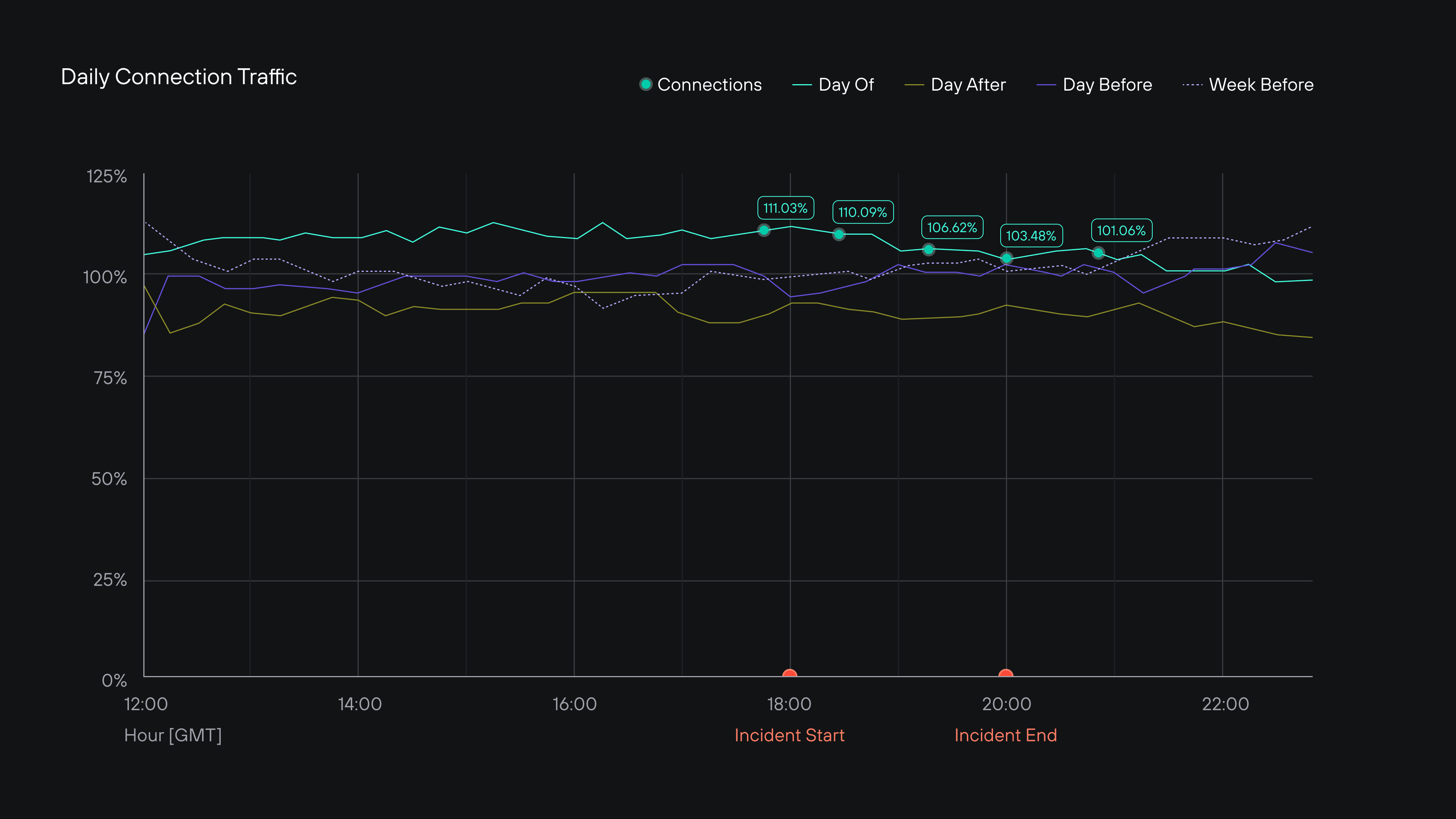
This is not a victory lap.
We watched the incident knowing what others were going through. And we worried that, at any moment, we could be managing a crisis, too. We also had the time to reflect on our efforts to design for survivability. For over nine consecutive quarters, Twingate has maintained >99.99% uptime. Back in 2021, we experienced a series of outages that forced us to rethink our approach to reliability. So this post shares some of what we learned: it might help us all build services that can survive such outages.
Today, as I watched colleagues (and even our competitors) start up the apologies, I was reminded of Twingate’s past. We’d been there before: the two-hour crash and recovery charts. Even if you’re only partially impacted, you have to do the tough work of explaining the impact. And, it’s not a V-shaped recovery when it looks like a horseshoe or the Grand Canyon.

Just one example of what LinkedIn looked like on June 12, 2025
Back in 2021, we faced the stark reality that lots of teams had to confront last week:
Even a company committed to best practices – automated deployments, frequent releases, 98% code coverage, comprehensive integration tests, smoke tests, and robust monitoring – can be brought to its knees by a single cloud provider's regional outage.
The key insights:
Good engineering practices alone don’t necessarily produce reliability.
A “single cloud” mentality places too much trust in a single point of failure.
We learned these lessons the hard way years ago, and we took on a large-scale redesign to avoid major outages. The fact that Twingate remained functional during the 6/12 event, even as many cloud services experienced catastrophic outages, is an outcome of the investment Twingate made in reliability.
Reliability is deeply integrated into Twingate’s engineering culture:
Every technical spec includes a dedicated reliability section, forcing engineers to consider it during feature design.
Our reliability team meets every three weeks to prioritize improvements.
We have automated monitoring, telemetry collection, alerting, and initial triage.
We spend time every day analyzing early signs that might be warnings of potential issues.
The Twingate Blueprint for Reliability
The Twingate cloud operates the way we expected the Internet to be: it's survivable. But how do we actually make that happen?
Building a highly available, reliable product means anticipating and mitigating against all sorts of potential issues, not just cloud outages. Because we had suffered through a cloud-provider outage, we realized adopting a 'single cloud' mentality or even a basic multi-cloud approach wasn't enough. Resilience requires going beyond conventional approaches.
We shifted to distributed, independent operation for services – and this philosophy has spread through our product, ultimately finding its way into how Twingate helps users work securely from anywhere. The manner in which we use P2P and direct connect to make connections and authentication distributed and survivable is also how we make the service resilient. We did what you’d expect:
Minimizing Blast Radius: We cannot prevent all errors. We isolate and contain their impact.
Decoupling Critical Services: We split our service into multiple, independently scalable deployments.
Multi-Region, Active-Active, and Beyond: In addition to geographically distributing our clusters, we ensure that each component can operate autonomously, minimizing dependencies.
Proactive Disaster Drills: We simulate failures of databases, clusters, and Redis. And we enhanced services to survive the failure of clusters without creating a thundering herd problem for other clusters.
Technical Solutions That Moved The Reliability Needle
We’ll get into the weeds in a future blog post, but for now let’s take a birds-eye-view of what actually had an impact on our reliability.
Smart Traffic Segmentation
When we experienced outages in 2021, the conventional wisdom would have been to break our Django monolith into microservices. But that approach would have been an organizational nightmare given our team size and timeline.
Instead, we take a pragmatic approach: we deploy the same codebase as several different services and use load balancer rules to route traffic based on criticality and latency requirements. This approach was fast to implement and had a massive impact on our resilience by containing and limiting the blast radius only to the impacted deployment .
Database Resilience
Previously, our database simply ran on Google's highly available infrastructure. We realized this created a single point of failure. We implemented:
Read replicas across multiple regions and multiple zones in each region
Automatic read-only mode during database issues
Review all flows and define clear separation between critical and non-critical writes: most of our critical connectivity flows are supported even when we are in a read-only mode
This approach means that even during database problems, core functionality continues to work.
Multi-Region Architecture
We expanded our control plane from a single region to multiple clusters across the US, running in an active-active configuration. For our data plane (which handles connection proxying), we went even farther—deploying globally across dozens of regions and multiple cloud providers. This wasn't just about reliability—it improved performance too. European users saw significantly reduced latency by connecting to clusters that are geographically closer.
Smarter Token Management for Uninterrupted Access
One of our most innovative solutions was implementing dual-expiration JWT tokens.
During our survivability work for the clusters, we realized that the smarter authentication for services could be used to ensure that Twingate clients and connectors have survivable connections, too.
This was the insight: the extension to JWT tokens that we used to make service communication survivable would allow clients to function even if the central server is down.
The token contains two expiration timestamps:
Short expiration (minutes) that operates during normal conditions
Long expiration (hours) that activates if our control plane is unreachable
This approach coupled with token prefetching (and a few security improvements to prevent abuse) creates a window to recover from even catastrophic outages without impacting ongoing sessions. User connections keep working even if the control plane goes down, mitigating one of the key issues with a centralized control plane architecture.
Building Survivable Services
We’ve had previous pressure tests: a NetworkChuck YouTube video on Twingate sent a thundering herd our way on a Friday evening and our traffic increased by 20x. The system survived that, too. But the best outcome about all the work we have done on survivability at Twingate is the little things: when we just work.
June 12th, 2025 was the ultimate real-world test of Twingate’s investment in reliability. Our VP of Engineering Eran Kampf posted on LinkedIn about Twingate surviving the GCP apocalypse, and the first comment was from a customer:
“Can confirm, we had no issues with Twingate yesterday!” - Joey Benamy, Sr Site Reliability Engineer, OncoLens
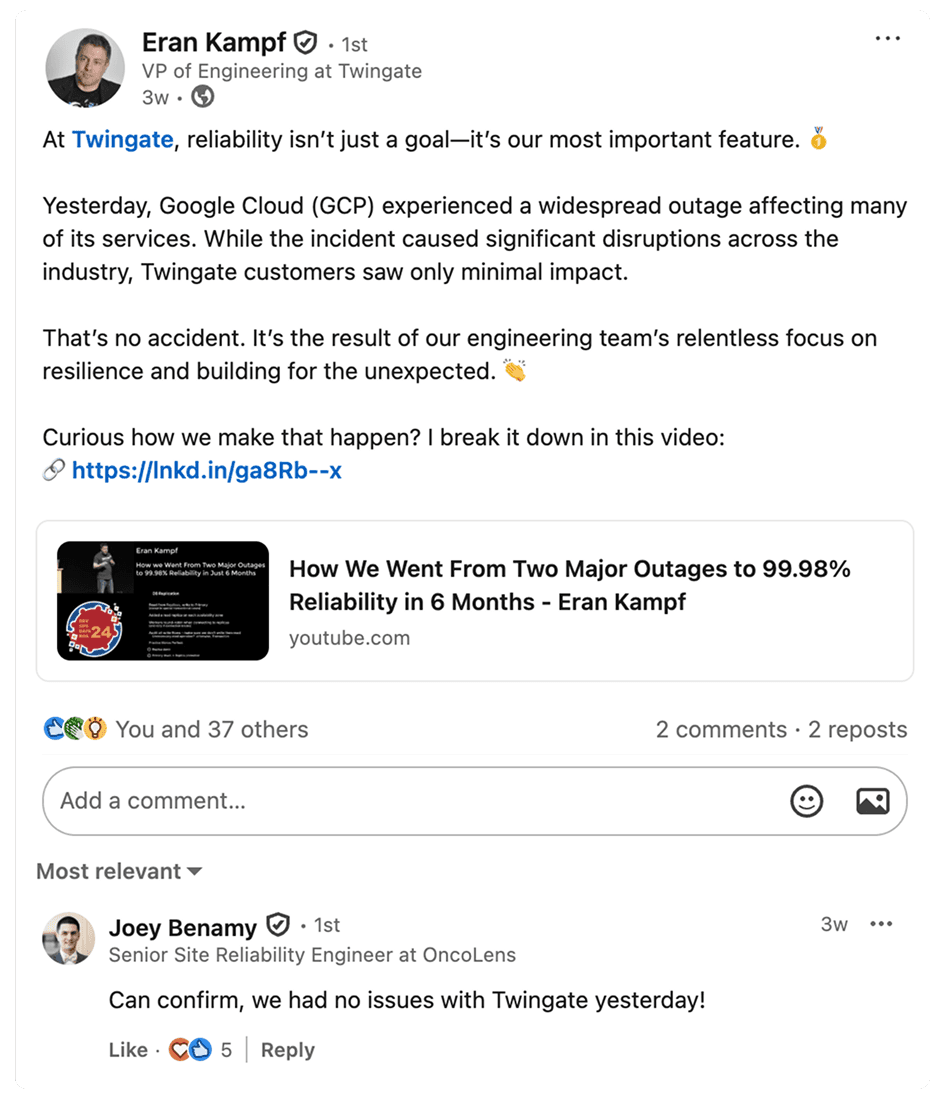
Thanks Joey! That’s the job :)
The 6/12 event was a powerful reminder that reliability extends beyond best practices within a single cloud environment. Continuous operation, especially for cloud infrastructure, demands innovation.
P2P and direct connect architectures, coupled with intelligent token-based authentication, offer a compelling alternative to traditional cloud network services. By decentralizing control, establishing direct communication paths, and enabling offline functionality, Twingate enables organizations to work from anywhere securely.
With support for Kubernetes environments, we enable cloud builders to build systems that are inherently more resilient to the inevitable failures that impact even the largest cloud providers.
If you’d like to learn more about the Twingate team’s work on resilience, Eran gave a talk about Twingate’s reliability journey at DevOps Days Boston
If you want to watch the video that spiked our traffic by 20X (and learn a little more about using Twingate, which is free), it’s still racking up views on YouTube
And if you’re building cloud services on Kubernetes, like us, maybe we can help out.
We have released an open-source Twingate Kubernetes Operator, a Python-based custom controller that automates the management of Twingate Zero Trust Network Access within Kubernetes environments.
This operator bridges the gap between Kubernetes' declarative resource model and Twingate's GraphQL API, enabling GitOps-style workflows for network access management. It can help you bring a little more resilience to your DevOps workflows, enabling "Zero Trust as Code" principles for the first time.
And if you are interested in expanding zero trust beyond network access, Twingate has more to offer for Kubernetes environments. Twingate Privileged Access for Kubernetes goes beyond the operator and supports precise, cluster-level access controls, streamlining authentication, authorization, and auditing.
Oh, and it's now available for testing in Early Access! Sign up if you’re ready to get your hands on it.
New to Twingate? We offer a free plan so you can try it out yourself, or you can request a personalized demo from our team.
Rapidly implement a modern Zero Trust network that is more secure and maintainable than VPNs.
How did Twingate stay up when the cloud broke?
Hint: Multi-cloud or hybrid cloud isn't enough.
Is it too soon to talk more about the Thursday, June 12, 2025 cloud outage? At Twingate, we love cloud services. Our cloud partners are critical to the scalability, ease of use, and security of Twingate... But they are not enough.
On June 12th, Google Cloud suffered a major outage that triggered a cascade of outages across the Internet, impacting the likes of Cloudflare, UPS, Spotify, Discord, and even Pokemon. But Twingate just kept running.
All cloud builders know what a major outage means: the triage, the fix, the apology tour, post-mortems. The true impact of outages extends far beyond the immediate technical problem:
Every incident derails development timelines by weeks.
Teams get pulled into endless damage-control meetings.
Sales, Support, and CS teams bear the emotional weight of frustrated customers.
Team morale takes a massive hit.
Because Twingate is the global network layer for our customers, any Twingate outage has an outsized impact. If we go down, our customers can’t access the resources they need to get work done.
So, when the June 12th outage erupted, we fired up the incident Zoom (as someone said, “I’m surprised this meeting is even working.”). We watched and waited for the alerts.
And Twingate just kept running. We had a range of alerts. We had our action plan ready-to-go and automation to pull in all the data needed to take action. Our team experienced the outage as end-users and as observers, but the Twingate service was not affected.
This is not a victory lap.
We watched the incident knowing what others were going through. And we worried that, at any moment, we could be managing a crisis, too. We also had the time to reflect on our efforts to design for survivability. For over nine consecutive quarters, Twingate has maintained >99.99% uptime. Back in 2021, we experienced a series of outages that forced us to rethink our approach to reliability. So this post shares some of what we learned: it might help us all build services that can survive such outages.
Today, as I watched colleagues (and even our competitors) start up the apologies, I was reminded of Twingate’s past. We’d been there before: the two-hour crash and recovery charts. Even if you’re only partially impacted, you have to do the tough work of explaining the impact. And, it’s not a V-shaped recovery when it looks like a horseshoe or the Grand Canyon.
Just one example of what LinkedIn looked like on June 12, 2025
Back in 2021, we faced the stark reality that lots of teams had to confront last week:
Even a company committed to best practices – automated deployments, frequent releases, 98% code coverage, comprehensive integration tests, smoke tests, and robust monitoring – can be brought to its knees by a single cloud provider's regional outage.
The key insights:
Good engineering practices alone don’t necessarily produce reliability.
A “single cloud” mentality places too much trust in a single point of failure.
We learned these lessons the hard way years ago, and we took on a large-scale redesign to avoid major outages. The fact that Twingate remained functional during the 6/12 event, even as many cloud services experienced catastrophic outages, is an outcome of the investment Twingate made in reliability.
Reliability is deeply integrated into Twingate’s engineering culture:
Every technical spec includes a dedicated reliability section, forcing engineers to consider it during feature design.
Our reliability team meets every three weeks to prioritize improvements.
We have automated monitoring, telemetry collection, alerting, and initial triage.
We spend time every day analyzing early signs that might be warnings of potential issues.
The Twingate Blueprint for Reliability
The Twingate cloud operates the way we expected the Internet to be: it's survivable. But how do we actually make that happen?
Building a highly available, reliable product means anticipating and mitigating against all sorts of potential issues, not just cloud outages. Because we had suffered through a cloud-provider outage, we realized adopting a 'single cloud' mentality or even a basic multi-cloud approach wasn't enough. Resilience requires going beyond conventional approaches.
We shifted to distributed, independent operation for services – and this philosophy has spread through our product, ultimately finding its way into how Twingate helps users work securely from anywhere. The manner in which we use P2P and direct connect to make connections and authentication distributed and survivable is also how we make the service resilient. We did what you’d expect:
Minimizing Blast Radius: We cannot prevent all errors. We isolate and contain their impact.
Decoupling Critical Services: We split our service into multiple, independently scalable deployments.
Multi-Region, Active-Active, and Beyond: In addition to geographically distributing our clusters, we ensure that each component can operate autonomously, minimizing dependencies.
Proactive Disaster Drills: We simulate failures of databases, clusters, and Redis. And we enhanced services to survive the failure of clusters without creating a thundering herd problem for other clusters.
Technical Solutions That Moved The Reliability Needle
We’ll get into the weeds in a future blog post, but for now let’s take a birds-eye-view of what actually had an impact on our reliability.
Smart Traffic Segmentation
When we experienced outages in 2021, the conventional wisdom would have been to break our Django monolith into microservices. But that approach would have been an organizational nightmare given our team size and timeline.
Instead, we take a pragmatic approach: we deploy the same codebase as several different services and use load balancer rules to route traffic based on criticality and latency requirements. This approach was fast to implement and had a massive impact on our resilience by containing and limiting the blast radius only to the impacted deployment .
Database Resilience
Previously, our database simply ran on Google's highly available infrastructure. We realized this created a single point of failure. We implemented:
Read replicas across multiple regions and multiple zones in each region
Automatic read-only mode during database issues
Review all flows and define clear separation between critical and non-critical writes: most of our critical connectivity flows are supported even when we are in a read-only mode
This approach means that even during database problems, core functionality continues to work.
Multi-Region Architecture
We expanded our control plane from a single region to multiple clusters across the US, running in an active-active configuration. For our data plane (which handles connection proxying), we went even farther—deploying globally across dozens of regions and multiple cloud providers. This wasn't just about reliability—it improved performance too. European users saw significantly reduced latency by connecting to clusters that are geographically closer.
Smarter Token Management for Uninterrupted Access
One of our most innovative solutions was implementing dual-expiration JWT tokens.
During our survivability work for the clusters, we realized that the smarter authentication for services could be used to ensure that Twingate clients and connectors have survivable connections, too.
This was the insight: the extension to JWT tokens that we used to make service communication survivable would allow clients to function even if the central server is down.
The token contains two expiration timestamps:
Short expiration (minutes) that operates during normal conditions
Long expiration (hours) that activates if our control plane is unreachable
This approach coupled with token prefetching (and a few security improvements to prevent abuse) creates a window to recover from even catastrophic outages without impacting ongoing sessions. User connections keep working even if the control plane goes down, mitigating one of the key issues with a centralized control plane architecture.
Building Survivable Services
We’ve had previous pressure tests: a NetworkChuck YouTube video on Twingate sent a thundering herd our way on a Friday evening and our traffic increased by 20x. The system survived that, too. But the best outcome about all the work we have done on survivability at Twingate is the little things: when we just work.
June 12th, 2025 was the ultimate real-world test of Twingate’s investment in reliability. Our VP of Engineering Eran Kampf posted on LinkedIn about Twingate surviving the GCP apocalypse, and the first comment was from a customer:
“Can confirm, we had no issues with Twingate yesterday!” - Joey Benamy, Sr Site Reliability Engineer, OncoLens
Thanks Joey! That’s the job :)
The 6/12 event was a powerful reminder that reliability extends beyond best practices within a single cloud environment. Continuous operation, especially for cloud infrastructure, demands innovation.
P2P and direct connect architectures, coupled with intelligent token-based authentication, offer a compelling alternative to traditional cloud network services. By decentralizing control, establishing direct communication paths, and enabling offline functionality, Twingate enables organizations to work from anywhere securely.
With support for Kubernetes environments, we enable cloud builders to build systems that are inherently more resilient to the inevitable failures that impact even the largest cloud providers.
If you’d like to learn more about the Twingate team’s work on resilience, Eran gave a talk about Twingate’s reliability journey at DevOps Days Boston
If you want to watch the video that spiked our traffic by 20X (and learn a little more about using Twingate, which is free), it’s still racking up views on YouTube
And if you’re building cloud services on Kubernetes, like us, maybe we can help out.
We have released an open-source Twingate Kubernetes Operator, a Python-based custom controller that automates the management of Twingate Zero Trust Network Access within Kubernetes environments.
This operator bridges the gap between Kubernetes' declarative resource model and Twingate's GraphQL API, enabling GitOps-style workflows for network access management. It can help you bring a little more resilience to your DevOps workflows, enabling "Zero Trust as Code" principles for the first time.
And if you are interested in expanding zero trust beyond network access, Twingate has more to offer for Kubernetes environments. Twingate Privileged Access for Kubernetes goes beyond the operator and supports precise, cluster-level access controls, streamlining authentication, authorization, and auditing.
Oh, and it's now available for testing in Early Access! Sign up if you’re ready to get your hands on it.
New to Twingate? We offer a free plan so you can try it out yourself, or you can request a personalized demo from our team.
Rapidly implement a modern Zero Trust network that is more secure and maintainable than VPNs.
How did Twingate stay up when the cloud broke?
Hint: Multi-cloud or hybrid cloud isn't enough.
Is it too soon to talk more about the Thursday, June 12, 2025 cloud outage? At Twingate, we love cloud services. Our cloud partners are critical to the scalability, ease of use, and security of Twingate... But they are not enough.
On June 12th, Google Cloud suffered a major outage that triggered a cascade of outages across the Internet, impacting the likes of Cloudflare, UPS, Spotify, Discord, and even Pokemon. But Twingate just kept running.
All cloud builders know what a major outage means: the triage, the fix, the apology tour, post-mortems. The true impact of outages extends far beyond the immediate technical problem:
Every incident derails development timelines by weeks.
Teams get pulled into endless damage-control meetings.
Sales, Support, and CS teams bear the emotional weight of frustrated customers.
Team morale takes a massive hit.
Because Twingate is the global network layer for our customers, any Twingate outage has an outsized impact. If we go down, our customers can’t access the resources they need to get work done.
So, when the June 12th outage erupted, we fired up the incident Zoom (as someone said, “I’m surprised this meeting is even working.”). We watched and waited for the alerts.
And Twingate just kept running. We had a range of alerts. We had our action plan ready-to-go and automation to pull in all the data needed to take action. Our team experienced the outage as end-users and as observers, but the Twingate service was not affected.
This is not a victory lap.
We watched the incident knowing what others were going through. And we worried that, at any moment, we could be managing a crisis, too. We also had the time to reflect on our efforts to design for survivability. For over nine consecutive quarters, Twingate has maintained >99.99% uptime. Back in 2021, we experienced a series of outages that forced us to rethink our approach to reliability. So this post shares some of what we learned: it might help us all build services that can survive such outages.
Today, as I watched colleagues (and even our competitors) start up the apologies, I was reminded of Twingate’s past. We’d been there before: the two-hour crash and recovery charts. Even if you’re only partially impacted, you have to do the tough work of explaining the impact. And, it’s not a V-shaped recovery when it looks like a horseshoe or the Grand Canyon.
Just one example of what LinkedIn looked like on June 12, 2025
Back in 2021, we faced the stark reality that lots of teams had to confront last week:
Even a company committed to best practices – automated deployments, frequent releases, 98% code coverage, comprehensive integration tests, smoke tests, and robust monitoring – can be brought to its knees by a single cloud provider's regional outage.
The key insights:
Good engineering practices alone don’t necessarily produce reliability.
A “single cloud” mentality places too much trust in a single point of failure.
We learned these lessons the hard way years ago, and we took on a large-scale redesign to avoid major outages. The fact that Twingate remained functional during the 6/12 event, even as many cloud services experienced catastrophic outages, is an outcome of the investment Twingate made in reliability.
Reliability is deeply integrated into Twingate’s engineering culture:
Every technical spec includes a dedicated reliability section, forcing engineers to consider it during feature design.
Our reliability team meets every three weeks to prioritize improvements.
We have automated monitoring, telemetry collection, alerting, and initial triage.
We spend time every day analyzing early signs that might be warnings of potential issues.
The Twingate Blueprint for Reliability
The Twingate cloud operates the way we expected the Internet to be: it's survivable. But how do we actually make that happen?
Building a highly available, reliable product means anticipating and mitigating against all sorts of potential issues, not just cloud outages. Because we had suffered through a cloud-provider outage, we realized adopting a 'single cloud' mentality or even a basic multi-cloud approach wasn't enough. Resilience requires going beyond conventional approaches.
We shifted to distributed, independent operation for services – and this philosophy has spread through our product, ultimately finding its way into how Twingate helps users work securely from anywhere. The manner in which we use P2P and direct connect to make connections and authentication distributed and survivable is also how we make the service resilient. We did what you’d expect:
Minimizing Blast Radius: We cannot prevent all errors. We isolate and contain their impact.
Decoupling Critical Services: We split our service into multiple, independently scalable deployments.
Multi-Region, Active-Active, and Beyond: In addition to geographically distributing our clusters, we ensure that each component can operate autonomously, minimizing dependencies.
Proactive Disaster Drills: We simulate failures of databases, clusters, and Redis. And we enhanced services to survive the failure of clusters without creating a thundering herd problem for other clusters.
Technical Solutions That Moved The Reliability Needle
We’ll get into the weeds in a future blog post, but for now let’s take a birds-eye-view of what actually had an impact on our reliability.
Smart Traffic Segmentation
When we experienced outages in 2021, the conventional wisdom would have been to break our Django monolith into microservices. But that approach would have been an organizational nightmare given our team size and timeline.
Instead, we take a pragmatic approach: we deploy the same codebase as several different services and use load balancer rules to route traffic based on criticality and latency requirements. This approach was fast to implement and had a massive impact on our resilience by containing and limiting the blast radius only to the impacted deployment .
Database Resilience
Previously, our database simply ran on Google's highly available infrastructure. We realized this created a single point of failure. We implemented:
Read replicas across multiple regions and multiple zones in each region
Automatic read-only mode during database issues
Review all flows and define clear separation between critical and non-critical writes: most of our critical connectivity flows are supported even when we are in a read-only mode
This approach means that even during database problems, core functionality continues to work.
Multi-Region Architecture
We expanded our control plane from a single region to multiple clusters across the US, running in an active-active configuration. For our data plane (which handles connection proxying), we went even farther—deploying globally across dozens of regions and multiple cloud providers. This wasn't just about reliability—it improved performance too. European users saw significantly reduced latency by connecting to clusters that are geographically closer.
Smarter Token Management for Uninterrupted Access
One of our most innovative solutions was implementing dual-expiration JWT tokens.
During our survivability work for the clusters, we realized that the smarter authentication for services could be used to ensure that Twingate clients and connectors have survivable connections, too.
This was the insight: the extension to JWT tokens that we used to make service communication survivable would allow clients to function even if the central server is down.
The token contains two expiration timestamps:
Short expiration (minutes) that operates during normal conditions
Long expiration (hours) that activates if our control plane is unreachable
This approach coupled with token prefetching (and a few security improvements to prevent abuse) creates a window to recover from even catastrophic outages without impacting ongoing sessions. User connections keep working even if the control plane goes down, mitigating one of the key issues with a centralized control plane architecture.
Building Survivable Services
We’ve had previous pressure tests: a NetworkChuck YouTube video on Twingate sent a thundering herd our way on a Friday evening and our traffic increased by 20x. The system survived that, too. But the best outcome about all the work we have done on survivability at Twingate is the little things: when we just work.
June 12th, 2025 was the ultimate real-world test of Twingate’s investment in reliability. Our VP of Engineering Eran Kampf posted on LinkedIn about Twingate surviving the GCP apocalypse, and the first comment was from a customer:
“Can confirm, we had no issues with Twingate yesterday!” - Joey Benamy, Sr Site Reliability Engineer, OncoLens
Thanks Joey! That’s the job :)
The 6/12 event was a powerful reminder that reliability extends beyond best practices within a single cloud environment. Continuous operation, especially for cloud infrastructure, demands innovation.
P2P and direct connect architectures, coupled with intelligent token-based authentication, offer a compelling alternative to traditional cloud network services. By decentralizing control, establishing direct communication paths, and enabling offline functionality, Twingate enables organizations to work from anywhere securely.
With support for Kubernetes environments, we enable cloud builders to build systems that are inherently more resilient to the inevitable failures that impact even the largest cloud providers.
If you’d like to learn more about the Twingate team’s work on resilience, Eran gave a talk about Twingate’s reliability journey at DevOps Days Boston
If you want to watch the video that spiked our traffic by 20X (and learn a little more about using Twingate, which is free), it’s still racking up views on YouTube
And if you’re building cloud services on Kubernetes, like us, maybe we can help out.
We have released an open-source Twingate Kubernetes Operator, a Python-based custom controller that automates the management of Twingate Zero Trust Network Access within Kubernetes environments.
This operator bridges the gap between Kubernetes' declarative resource model and Twingate's GraphQL API, enabling GitOps-style workflows for network access management. It can help you bring a little more resilience to your DevOps workflows, enabling "Zero Trust as Code" principles for the first time.
And if you are interested in expanding zero trust beyond network access, Twingate has more to offer for Kubernetes environments. Twingate Privileged Access for Kubernetes goes beyond the operator and supports precise, cluster-level access controls, streamlining authentication, authorization, and auditing.
Oh, and it's now available for testing in Early Access! Sign up if you’re ready to get your hands on it.
New to Twingate? We offer a free plan so you can try it out yourself, or you can request a personalized demo from our team.
Solutions
Solutions
The VPN replacement your workforce will love.
Solutions